This post is republished from the Chronosphere blog. With Chronosphere’s acquisition of Calyptia in 2024, Chronosphere became the primary corporate sponsor of Fluent Bit. Eduardo Silva — the original creator of Fluent Bit and co-founder of Calyptia — leads a team of Chronosphere engineers dedicated full-time to the project, ensuring its continuous development and improvement.
Introduction
Fluent Bit is a widely used open-source data collection agent, processor, and forwarder that enables you to collect logs, metrics, and traces from various sources, filter and transform them, and then forward them to multiple destinations. With over ten billion Docker pulls, Fluent Bit has established itself as a preferred choice for log processing, collecting, and shipping.
At its core, Fluent Bit is a simple data pipeline consisting of various stages, as depicted below.
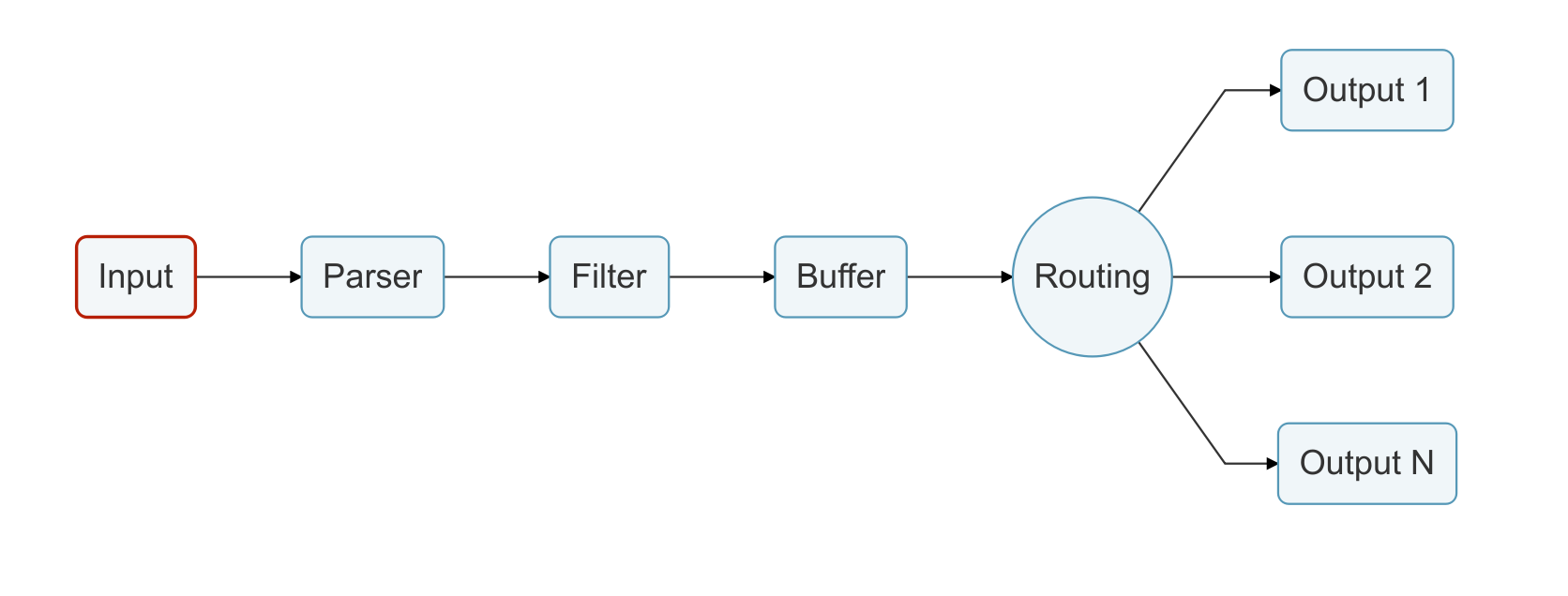 Most data pipelines eventually suffer from backpressure, which is when data is ingested at a higher rate than the ability to flush it. Backpressure causes problems such as high memory usage, service downtime, and data loss. Network failures, latency, or third-party service failures are common scenarios where backpressure occurs.
Most data pipelines eventually suffer from backpressure, which is when data is ingested at a higher rate than the ability to flush it. Backpressure causes problems such as high memory usage, service downtime, and data loss. Network failures, latency, or third-party service failures are common scenarios where backpressure occurs.
Fluent Bit offers special strategies to deal with backpressure to help ensure data safety and reduce downtime. Recognizing when Fluent Bit is experiencing backpressure and knowing how to address it is crucial for maintaining a healthy data pipeline.
This post provides a practical guide on how to detect and avoid backpressure problems with Fluent Bit.
Prerequisites
- Docker: Installed on your local machine.
- Familiarity with Fluent Bit concepts: Such as, inputs, outputs, parsers, and filters. If you’re not familiar with these concepts, please refer to the official documentation.
The default: memory-based buffering
In Fluent Bit, records are emitted by an input plugin. These records are then grouped together by the engine into a unit called a Chunk, which typically has a size of around 2MB. Based on the configuration, the engine determines where to store these Chunks. By default, all Chunks are created in memory.
With the default mechanism, Fluent Bit will store data in memory as much as possible. This is the fastest mechanism with the least system overhead, but in certain scenarios, data can be ingested at a higher rate than the ability to flush it to some destinations. This generates backpressure, leading to high memory consumption in the service.
Network failures, latency, or unresponsive third-party services are common scenarios where we cannot deliver data fast enough as we receive new data to process, which leads to backpressure.
In a high-load environment with backpressure, there’s a risk of increased memory usage, which leads to the termination of the Fluent Bit process by the Kernel.
Let’s see a demo where Fluent Bit is running in a constrained environment, which causes backpressure, leading to getting killed by Kernel (OOM).
Instructions
Clone the Samples Git Repository:
This repository contains all the required configuration files. Use the command below to clone the repository.
|
|
Evaluating Default RAM Consumption:
|
|
The above command runs Fluent Bit in a docker container with an empty configuration file; this lets us evaluate what the default memory consumption and memory limits for the container.
Use the docker ps command to get the name or container ID of the newly created
container and use that value in the below command to get its stats.
|
|
The image below shows that by default, the container consumes 10MB of RAM and can take up to 8GB of system RAM.
 Fluent Bit Configuration
Fluent Bit Configuration
|
|
The above configuration uses the dummy input plugin to generate large amounts of data for test purposes. We have configured it to generate 1500 records per second. This data is then printed to the console using the stdout output plugin.
Simulating Backpressure
To simulate OOM kill behavior caused due to backpressure, we will generate data at a higher rate while restricting the container RAM to just 20MB. With this configuration as Fluent Bit tries to buffer more data in memory it will eventually hit the imposed RAM limit of the container and the service will crash.
Execute the below command and observe the result.
|
|
After a few seconds, the container will stop automatically. Once it stops, grab
the container ID using docker ps -a and inspect the container—you should
observe that it was killed due to a container Out Of Memory error.

 This demonstrates how backpressure in Fluent Bit leads to increased memory usage, resulting in the Kernel terminating the application upon reaching memory limits, which causes downtime and data loss.
This demonstrates how backpressure in Fluent Bit leads to increased memory usage, resulting in the Kernel terminating the application upon reaching memory limits, which causes downtime and data loss.
If your Fluent Bit process is continuously getting killed, it is likely an indication that Fluent Bit is experiencing backpressure. In the following section, we’ll explore a solution to this problem.
A quick fix: limiting memory-based buffering
A workaround for backpressure scenarios like the above is to limit the amount of
memory in records that an input plugin can register. This can be configured
using the mem_buf_limit property. If a plugin has enqueued more than the
mem_buf_limit, it won’t be able to ingest more until that buffered data is
delivered.
When the set limit is reached, the specific input plugin gets paused, halting record ingestion until resumed, which inevitably leads to data loss.
When an input plugin is paused, Fluent Bit logs the information on the console with an example shown below:
|
|
The workaround of mem_buf_limit is good for certain scenarios and
environments, it helps to control the memory usage of the service, but at the
cost of data loss. This can happen with any input plugin.
The goal of mem_buf_limit is memory control and survival of the service. Let’s
see what happens when we modify our Fluent Bit configuration by adding the
mem_buf_limit property to our input plugin.
|
|
We’ve set a 20MB memory limit for the container. With Fluent Bit using 10MB in its default configuration, we allocated an additional 10MB as mem_buf_limit.
Note: The combined memory limit assigned to each input plugin, must be lower than the resource restriction placed on the container.
Execute the below command and observe the result.
|
|
Unlike the previous scenario, the container is not killed and continues to emit
dummy records on the console. Grab the container ID using docker ps and
execute the below command.
|
|
 The above image indicates that as Fluent Bit reaches the 10MB buffer limit of the input plugin, it pauses ingesting new records, potentially leading to data loss, but this pause prevents the service from getting terminated due to high memory usage. Upon buffer clearance, the ingestion of new records resumes.
The above image indicates that as Fluent Bit reaches the 10MB buffer limit of the input plugin, it pauses ingesting new records, potentially leading to data loss, but this pause prevents the service from getting terminated due to high memory usage. Upon buffer clearance, the ingestion of new records resumes.
If you are observing the above logs in Fluent Bit, it is a sign of Fluent Bit hitting the configured memory limits at input plugins due to backpressure. Check out this blog post on how to configure alerts from logs using Fluent Bit.
In the upcoming section, we will see how to achieve both data safety and memory safety.
A permanent fix: filesystem-based buffering
Filesystem buffering provides control over backpressure and can help guarantee data safety. Memory and filesystem buffering approaches are not mutually exclusive. When filesystem buffering is enabled for your input plugin, you are getting the best of both worlds: performance and data safety.
When Filesystem buffering is enabled, the behavior of the engine is different. Upon
Chunk creation, the engine stores the content in memory and also maps a copy on disk
(through mmap(2)). The newly
created Chunk is (1) active in memory, (2) backed up on disk.
How does the Filesystem buffering mechanism deal with high memory usage and
backpressure? Fluent Bit controls the number of Chunks that are up in
memory. By default, the engine allows us to have 128 Chunks up in memory, this
value is controlled by service property storage.max_chunks_up. The active
Chunks that are up are ready for delivery.
Any other remaining Chunk is in a down state, which means that it is only in
the filesystem and won’t be up in memory unless it is ready to be delivered.
Remember, chunks are never much larger than 2 MB, thus the default
storage.max_chunks_up value of 128, each input is limited to roughly 256 MB of
memory.
If the input plugin has enabled storage.type as filesystem, when reaching
the storage.max_chunks_up threshold, instead of the plugin being paused, all
new data will go to Chunks that are down in the filesystem. This allows us to
control the memory usage of the service and also provides a guarantee that the
service won’t lose any data.
Let’s modify our Fluent Bit configuration by enabling filesystem buffering.
|
|
In the above configuration, we have added storage.type as filesystem in our
input plugin and a [SERVICE] block to configure
storage.storage.max_chunks_up to 5 (~10MB)
Execute the below command and observe the result.
|
|
Unlike the default scenario, the container does not crash and continues to emit
dummy records on the console. When the storage.storage.max_chunks_up limit is
reached, the chunks are backed up in the filesystem and delivered once the
memory is free.
Note: While file system-based buffering helps prevent container crashes due to backpressure, it introduces new considerations related to filesystem limits. It’s important to know that just as memory can be exhausted, so can filesystem storage. When opting for filesystem-based buffering, it is essential to incorporate a plan that addresses potential filesystem-related challenges.
Conclusion
This guide has explored effective strategies to manage backpressure and prevent
data loss in Fluent Bit. We’ve highlighted the limitations of default
memory-based buffering and how Mem_Buf_Limit is a quick fix to balance memory
usage. The ultimate solution, filesystem-based buffering, offers a comprehensive
approach, ensuring data safety and efficient memory management. These techniques
are essential for optimizing Fluent Bit in high-throughput environments,
ensuring robust and reliable log processing.
 For more information on this topic, refer to the documentation below
For more information on this topic, refer to the documentation below
You may also be interested in
To continue expanding your Fluent Bit knowledge, check out Fluent Bit Academy. It’s filled with on-demand videos guiding you through all things Fluent Bit — best practices and how-to’s on advanced processing rules, routing to multiple destinations, and much more.
