Thousands of organizations use Fluent Bit and Fluentd to collect, process, and ship their data from Kubernetes, cloud infrastructure, network devices, and other sources. These organizations may uniquely deploy Fluent Bit and Fluentd; however, many users share common architecture patterns.
In this blog, we will talk about 3 of the most common architectures that users leverage when deploying Fluent Bit and Fluentd:
- Forwarder’s and Aggregators
- Side car / Agent deployment
- Network device aggregator
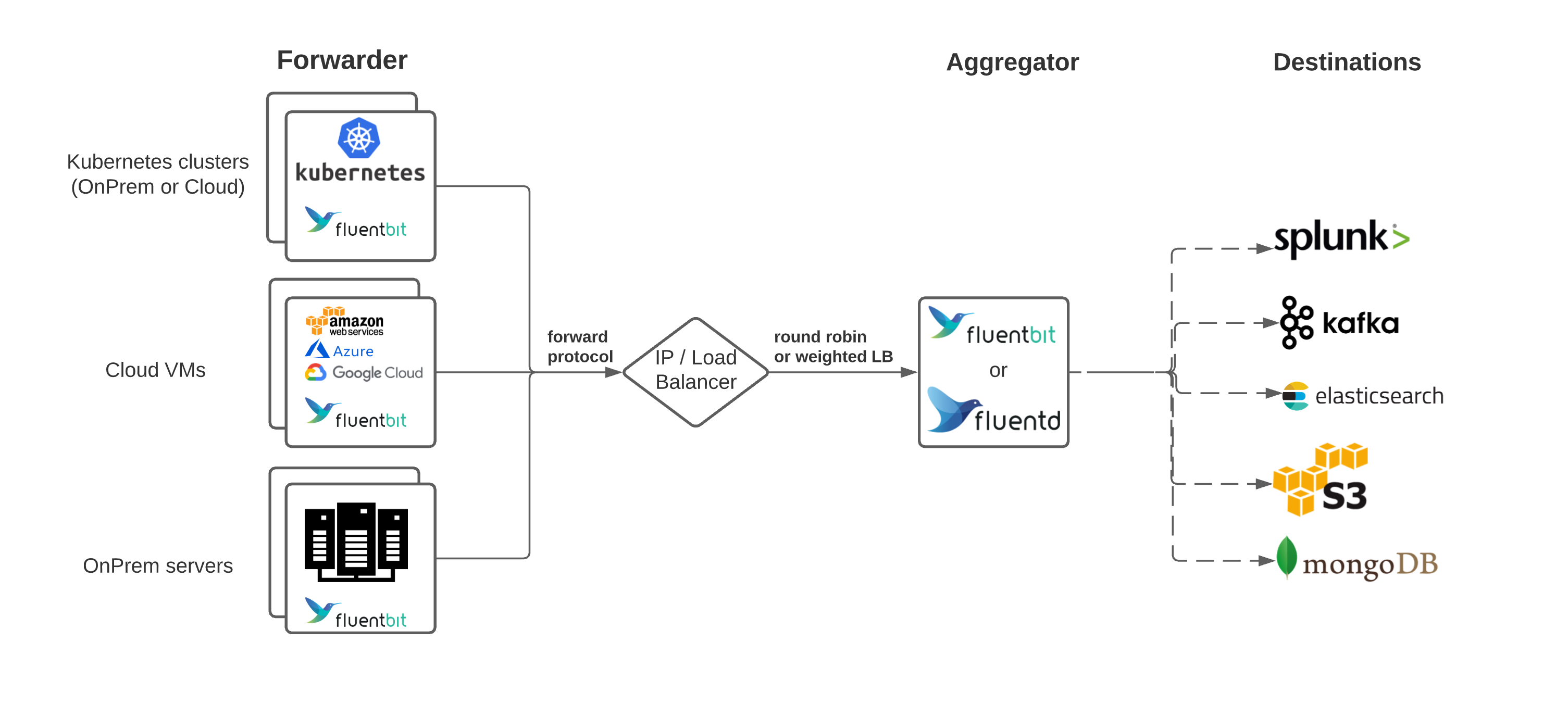
Forwarder and Aggregator
One of the more common patterns for Fluent Bit and Fluentd is deploying in what is known as the forwarder/aggregator pattern. This pattern includes having a lightweight instance deployed on edge, generally where data is created, such as Kubernetes nodes or virtual machines. These forwarders do minimal processing and then use the forward protocol to send data to a much heavier instance of Fluentd or Fluent Bit. This heavier instance, known as the aggregator, may perform more filtering and processing before routing to the appropriate backend(s).
This filtering can include routing messages to different endpoints depending on different message values, adding fields to every message sent, or redacting values for privacy/security concerns.
Advantages
- Less resource utilization on the edge devices (maximize throughput)
- Allow processing to scale independently on the aggregator tier.
- Easy to add more backends (configuration change in aggregator vs. all forwarders)
Disadvantages
- Dedicated resources required for an aggregation instance
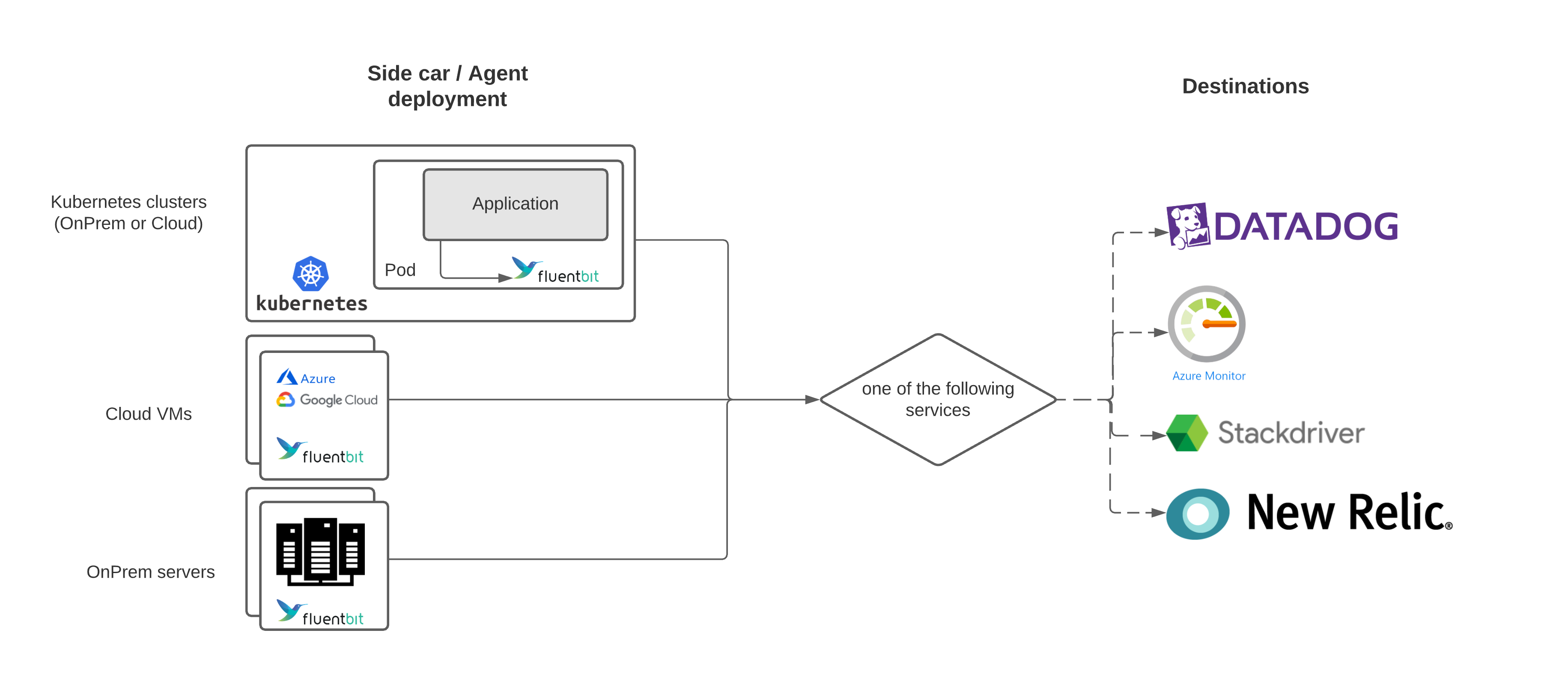
Sidecar / Agent deployment
Similar to the forwarder deployment, the sidecar/agent model uses deploying Fluentd and Fluent Bit on edge. However, instead of sending data to an aggregator, the sidecar/agents send data directly to a backend service. This method works great if you only have a single backend you need to send data to and is used by cloud giants such as Microsoft, Google, and Amazon when they leverage Fluent Bit as part of their offerings: Azure Log Analytics, Google Cloud Operations Suite (formerly Stackdriver), and AWS.
Within Kubernetes, this architecture can be further broken down into deploying as a DaemonSet (one agent per Kubernetes node) or deployed inside the same Kubernetes pod as the application. The latter of the Kubernetes specific deployment is useful when log processing from container logs might not prove to be as efficient as directly reading from an application (E.g., Java multi-line processing).
Advantages
- No aggregator is needed; each agent handles backpressure.
Disadvantages
- Hard to change configuration across a fleet of agents (E.g., adding another backend or processing)
- Hard to add more end destinations if needed
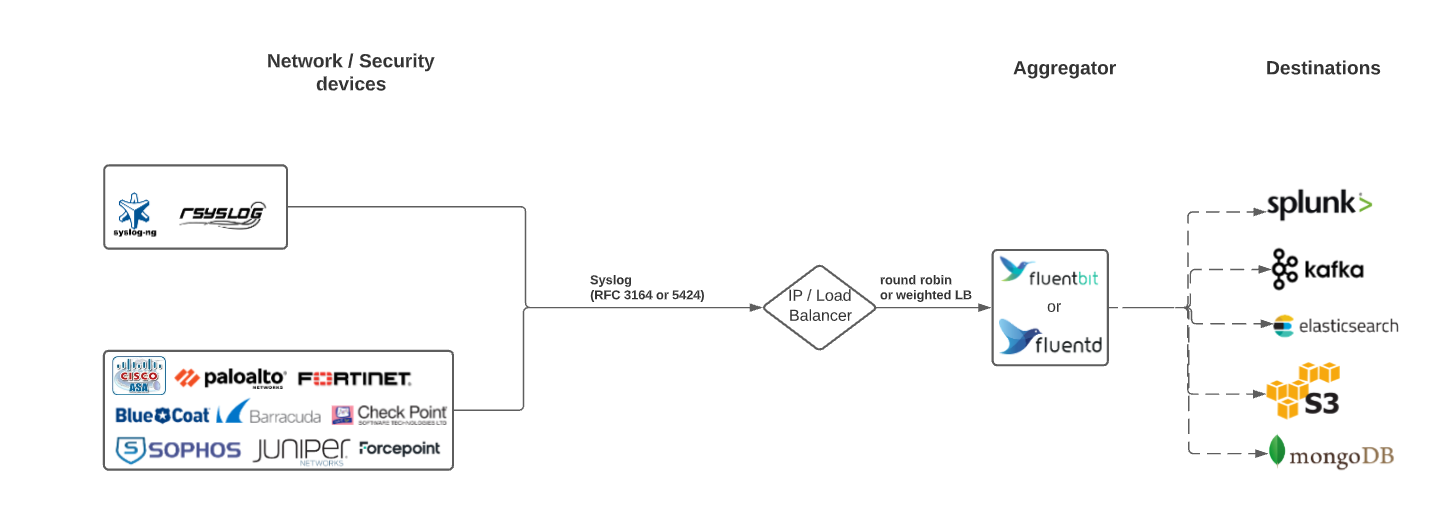
Network Device / Syslog aggregator
While Fluentd and Fluent Bit are Cloud Native Computing Foundation (CNCF) projects, they also work very well with legacy logging infrastructure such as Network / Syslog / Firewall devices. One of the most popular inputs for Fluentd and Fluent Bit includes syslog. Some users have deployed pure aggregators to capture all the logs and route to security-focused backends. These aggregators can also include logic to redact certain messages or process messages in a more usable way for security applications in end destinations.
Advantages
- No agents required; Primarily read from Syslog.
- Add processing after data is sent, such as IP redaction, and scale independently.
Disadvantages
- More processing might be needed depending on the input.
- Troubleshooting might be more involved with black-box network devices.
Conclusion
Fluentd and Fluent Bit are powerful and flexible applications that you can use as part of your data, observability, and security pipelines. Knowing more about common architecture patterns can help you make your decision to deploy Fluentd and Fluent Bit.
We invite you to discuss these architecture patterns further with us in the Fluent Slack channel, GitHub, or even email. Additionally, if you have feedback on Fluentd, Fluent Bit, or the Fluent Ecosystem, we would appreciate it if you could fill out the following survey.