Fluentd and Fluent Bit are popular open-source Cloud Native Computing Foundation (CNCF) projects used for collecting data from many sources and shipping to a variety of backends such as Splunk, Elasticsearch, and Kafka, to name a few.
As data increases within organizations, a single backend can put organizations at a disadvantage due to cost, use cases, and different stakeholders needing the same data (E.g., security and operations). Instead of installing multiple agents, users can leverage Fluentd and Fluent Bit to collect and route data to various backends. Additionally, with Fluent Bit’s latest release, 1.6, users can now also use stream processing to route data to multiple locations and perform logic before sending data.
Example use cases of Fluent Bit stream processing include:
- Reducing log volume sent to a single location
- Performing calculations before sending data to a backend (E.g., calculate the number of Nginx 404 errors in a 1-minute window)
- Time series predictions for when an application may consume too much memory
This blog walks through these use cases and how to leverage Fluent Bit’s new stream processing features with a standard data pipeline.
Environment
We will be using two Google Cloud Virtual Machines, one with Fluent Bit and Nginx installed and the other with Splunk Enterprise installed.
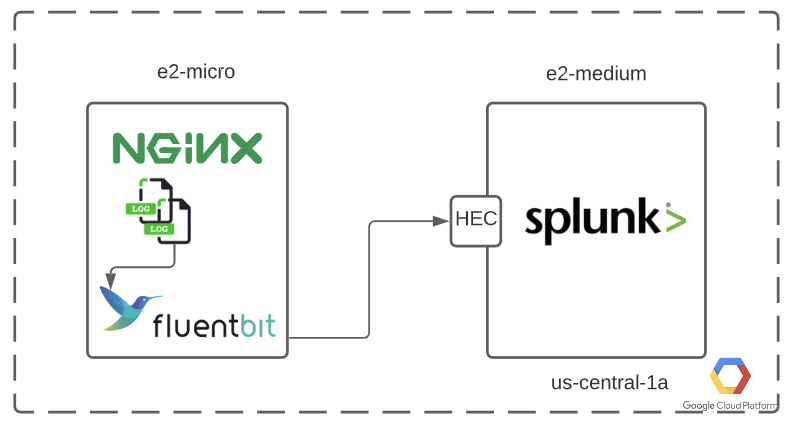
Intro to Stream Processing
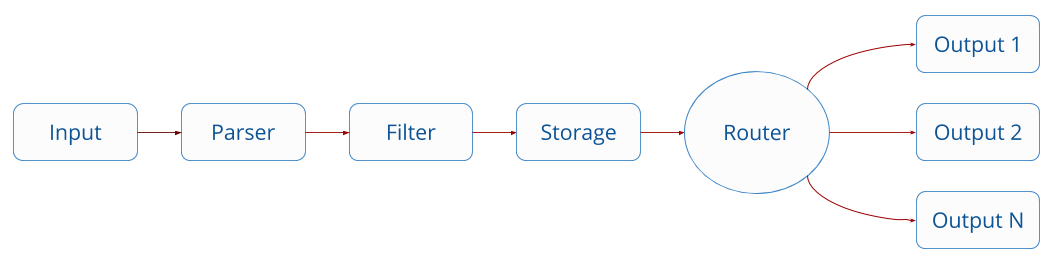
To understand how the stream processor for Fluent Bit works, we need a quick overview of Fluent Bit’s basic architecture. Fluent Bit has a plugin structure: Inputs, Parsers, Filters, Storage, and finally Outputs. In our Nginx to Splunk example, the Nginx logs are input with a known format (parser). They have no filtering, are stored on disk, and finally sent off to Splunk.
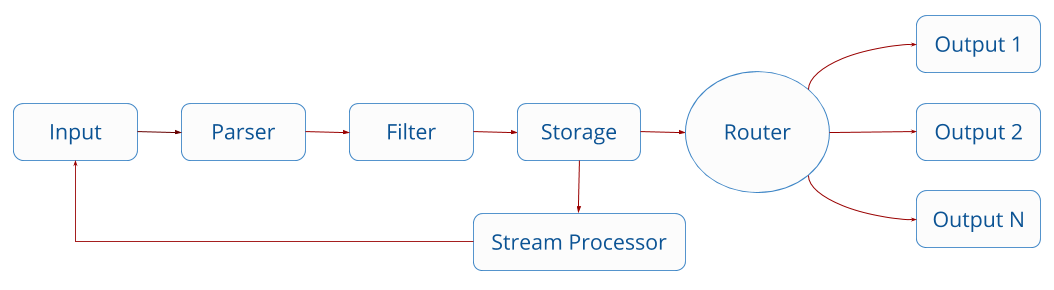
With the Stream Processor, we add a new box to the flow where data in storage can be processed and sent back to Fluent Bit for more processing.
Use Case 1: Reducing Log volume sent to a single location
While Fluent Bit has a robust tagging system, you can also use the stream processor to route events to different end destinations. In our Nginx use case, we will send all 200 logs to an output file on our local machine vs. sending it off to Splunk.To achieve this, we will create new stream_processing.conf file in /etc/td-agent-bit/ and from there add the following
[STREAM_TASK]
Name http_200_code
Exec CREATE STREAM http200 WITH (tag='http200') AS SELECT * FROM TAG:'nginx' WHERE code='200';
In this example, I take the known format of an Nginx log and then SELECT the entire record, including the response code 200. I also add another output in the configuration to send those records to an output file.
My full configuration looks like the following.
[SERVICE]
flush 5
log_level info
parsers_file parsers.conf
streams_file streams.conf
[INPUT]
name tail
path /var/log/nginx/*.log
parser nginx
tag nginx
read_from_head true
[OUTPUT]
Name file
Format out_file
Match http200
Path /var/log/
[OUTPUT]
Name splunk
Match *
Host XXXXXXXXXXX
Splunk_Token XXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
TLS On
TLS.Verify Off
Splunk_Send_Raw Off
Use Case 2: Performing Calculations before sending to a backend
In many cases, backend systems give me robust aggregation and calculation abilities, allowing me to determine averages, minimums, and pct95s across all my stored data. However, in cases where I may be sending to an object store such as S3, Google Cloud Storage, Azure Blob, I may wish to perform these calculations before sending manually.To add this to the Stream Processor, we will add the following to the stream processing configuration and remove our old logic. Our new streams.conf looks like the following
[STREAM_TASK]
Name agg_http_404
Exec CREATE STREAM http404agg WITH (tag='http404agg') AS SELECT COUNT(*) AS total404 FROM TAG:'nginx' WINDOW TUMBLING (15 SECOND) WHERE code='404';
This new configuration includes a rolling window of 1 minute and calculation of how many 404 errors occurred in 15 seconds and then outputs a log that looks like the following.
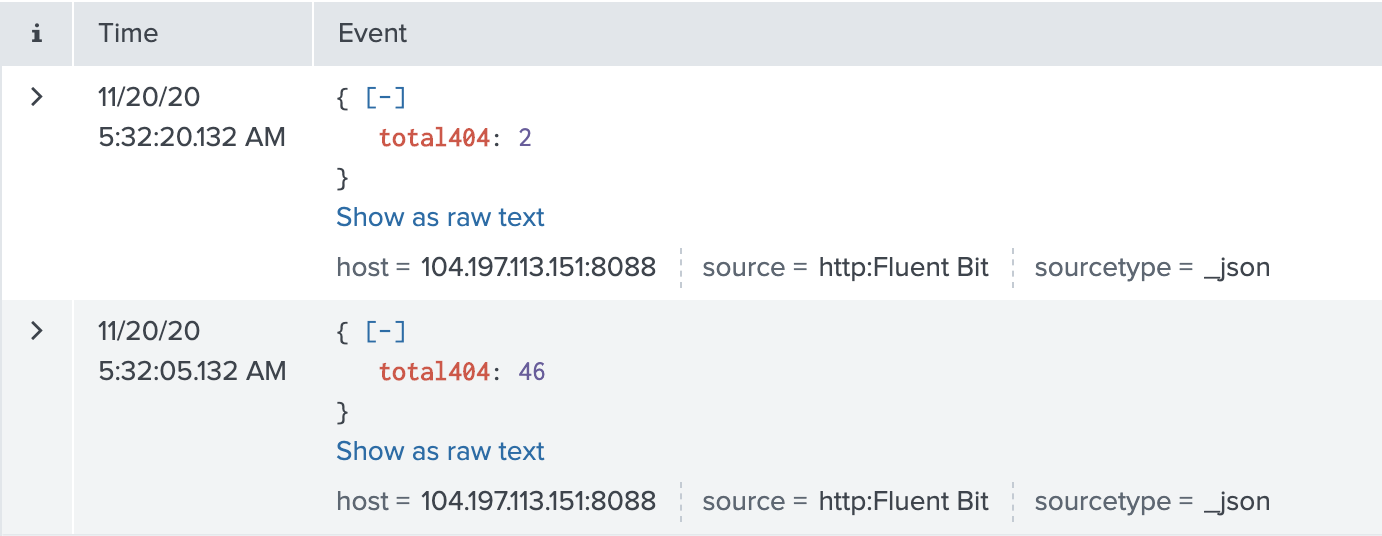
While in our use case, the amount of data saved is small, aggregating across 10,000 messages/second could be extremely powerful.
Use Case 3: Time series forecasting when an application may consume too much memory
While Fluent Bit is not traditionally viewed as a metric collector, it’s default plugin suite include CPU, Memory, Disk, and Network metrics stats. One of the more powerful Stream Processing functions contained in Fluent Bit 1.6 is time series forecasting. This Stream Processing allows users to forecast time series metrics based on rolling windows of existing data.
Let’s try an example on top of System memory.We’ll add the following Input plugin to the configuration file td-agent-bit.conf.
[INPUT]
name mem
alias memory
Tag memory
Then we will add the forecasting to streams.conf file.
[STREAM_TASK]
Name forecast_mem
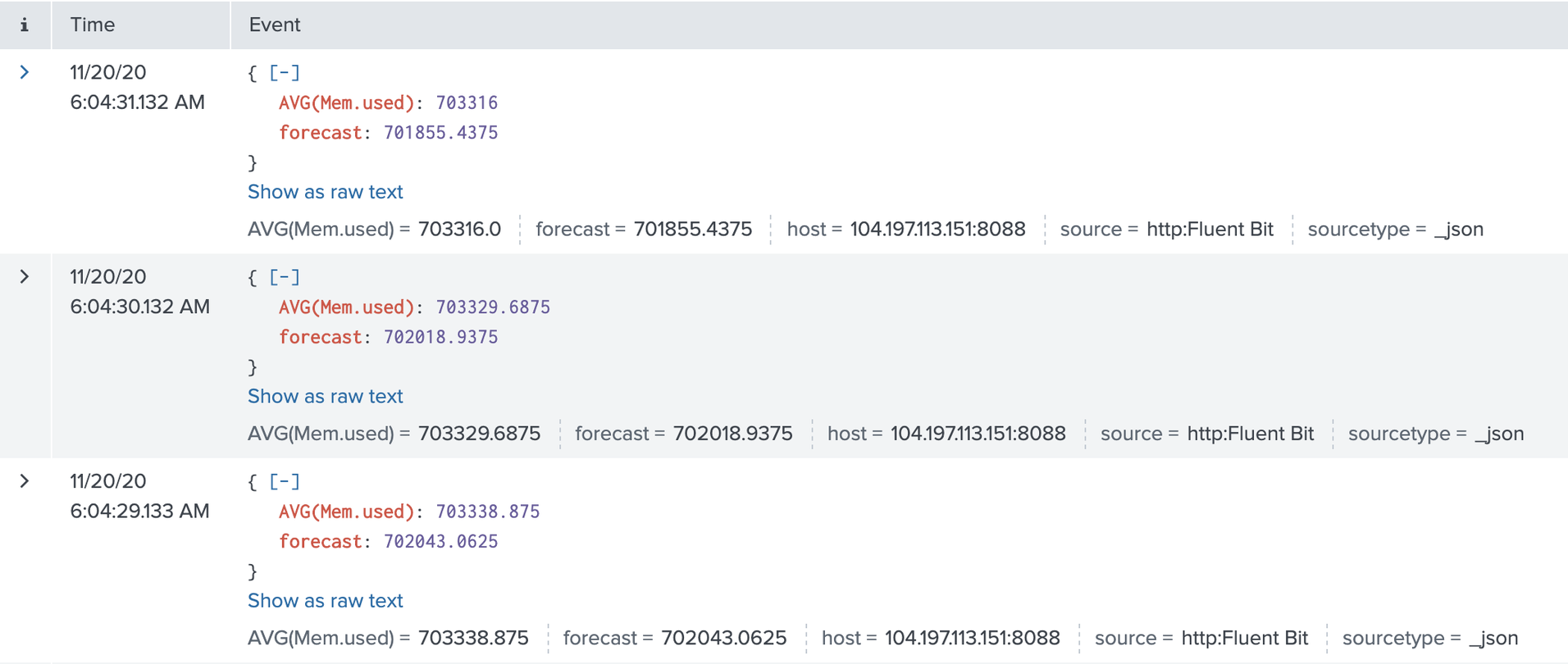
Exec CREATE STREAM forecast_mem AS SELECT AVG(Mem.used), timeseries_forecast(RECORD_TIME(), Mem.used, 125) AS forecast FROM STREAM:memory WINDOW HOPPING (100 SECOND, ADVANCE BY 1 SECOND);
In our use case, we generate a forecasting value that will look at a window of 100 seconds, advanced by 1 second or 100 samples. Then we will predict the memory used 125 seconds into the future. Our new record, in this case, will include the average memory and the forecast.
Conclusion
Fluent Bit Stream Processing is a brand new tool that users can leverage when building their logging and observability pipelines. Fluent Bit 1.6 also includes powerful plugin support for TensorFlow lite lending to even more use cases.
We are excited to see all the use cases that the community creates. We invite you to share them with us in the Fluent Slack channel, GitHub, or even email. Additionally, if you have feedback on Fluentd, Fluent Bit, or the Fluent Ecosystem, we would appreciate your feedback for the following survey.